

Publication's
Here we publish information on studies that are directly or indirectly related to our solutions or applied technologies, or persons from our companies.
Semantische Datenintelligenz im Einsatz

Editors: Ege, Börteçin, Paschke, Adrian (Hrsg.) diverse Autoren,
eBook ISBN 978-3-658-31938-0 | DOI 10.1007/978-3-658-31938-0 | Softcover ISBN 978-3-658-31937-3
Kapitel 11: «Semiotik, ein Schlüsselelement für Systeme mit künstlicher Intelligenz»
Autor: Walter Diggelmann, ai-one™
Automatisierte Systeme, die künstliche Intelligenz zur Textanalyse nutzen, sind auf dem Vormarsch. Sie sollen die Botschaft eines Textes verstehen, sie in den Kontext einordnen und feststellen, ob sie eine negative, positive oder neutrale Haltung zu einem Thema zum Ausdruck bringt. Botschaften können auf viele Arten und aus unterschiedlichen Perspektiven interpretiert werden. Ein Empfänger berücksichtigt nicht nur den Inhalt, sondern auch die Absicht des Absenders - die aber nicht mit der beabsichtigten Bedeutung übereinstimmen muss. Um Missverständnisse zu vermeiden, muss der Kontext der Kommunikation klar sein. Damit die semantische Textanalyse - die die Grundlage für ML-, IoT- und KI-Lösungen bildet - effektiv funktioniert, muss sie dynamische Antworten auf zwei zentrale Herausforderungen der Textanalyse liefern.
Syntaktisch kongruente Sätze und Formulierungen, die aus unterschiedlichen zeitlichen oder kulturellen Kontexten stammen, können trotz ihrer strukturellen Gleichwertigkeit ganz unterschiedliche Bedeutungen oder Botschaften vermitteln.
Hans-Georg Gadamer beschreibt in seinem Werk Wahrheit und Methode den hermeneutischen Zirkel wie folgt: "Das Ganze muss vom Einzelnen her verstanden werden, und das Einzelne vom Ganzen her." Dieser Zirkel enthält also ein Paradox: Das, was verstanden werden soll, muss in gewisser Weise bereits vorher verstanden oder zumindest teilweise bekannt sein.

NASA - Marshall Space Flight Center Research and Technology Report 2015
https://ntrs.nasa.gov/citations/20160006403
The investments in technology development we made in 2015 not only support the Agency's current missions, but they will also enable new missions. Some of these projects will allow us to develop an in-space architecture for human space exploration; Marshall employees are developing and testing cutting-edge propulsion solutions that will propel humans in-space and land them on Mars. Others are working on technologies that could support a deep space habitat, which will be critical to enable humans to live and work in deep space and on other worlds. Still others are maturing technologies that will help new scientific instruments study the outer edge of the universe-instruments that will provide valuable information as we seek to explore the outer planets and search for life.
Document ID 20160006403
Report Number M16-5259 | NASA/TM-2016-218221

Artificial Intelligence Agents to Support Data Mining for Early Stage of Space Systems Design
978-1-7281-2734-7/20/ ©2020 IEEE
The complex and multidisciplinary nature of space systems and mission architectures is especially evident in early stage of design and architecting, where systems stakeholders have to keep into account all the aspects of a project, including alternatives, cost, risk, and schedule and evaluate various potentially conflicting metrics with a high level of uncertainty. Though aerospace engineering is a relatively young discipline, stakeholders in the field can rely on a vast body of knowledge and good practices for space systems design and architecting of space missions. These guidelines have been identified and refined over the years.
However, the increase in size and complexity of applications in the aerospace discipline highlighted some gaps in this approach: first, the amount of available information is now very large and originates from multiple sources, often with diverse representations, and useful data for trade space analysis or analysis of all potential alternatives can be easily overlooked.
Second, the variety and complexity of the systems involved and of the different domains to be kept into account can generate unexpected interactions that cannot be easily identified; third, continuous advancements in the field of aerospace resulted in the development of new approaches and methodologies, for which a common knowledge database is not existing yet, thus requiring substantial effort upfront.
To address these gaps and support both decision making in early stage of space systems design and increased automation in extraction of necessary data to feed working groups and analytical methodologies, we propose the training and use of Artificial Intelligence agents. These agents can be trained to recognize not only information coming from standardized representations, for example Model Based Systems Engineering diagrams, but also descriptions of systems and functionalities in plain English.
This capability allows each agent to quantify the relevance of publications and documents to the query for which it is trained. At the same time, each agent can recognize potentially useful information in documents which are only loosely connected to the systems or functionalities on which the agent has been trained, and which would possibly be overlooked in a traditional literature review. The search for pertinent sources can be further refined using keywords, that let the user specify more details about the systems or functionality of interest, based on the intended use of the data. In this work we illustrate the use of Artificial Intelligent agents to sort space habitat subsystems into NASA Technology Roadmaps categories and to identify relevant sources of data for these subsystems. We demonstrate how the agents can support the retrieval of complex information required to feed existing System-of-Systems analytic tools and discuss challenges of this approach and future steps.

Wissensorganisation und -repräsentation mit digitalen Technologien
https://www.degruyter.com/view/product/205460
Hrsg. v. Keller, Stefan Andreas / Schneider, René / Volk, Benno / Walter Diggelmann (Page 128 - 145)
Der Band präsentiert in einem umfassenden Überblick eine große Bandbreite an konzeptionellen und technologischen Ansätzen zur Modellierung und digitalen Repräsentation von Wissen in Wissensorganisationen (wie Universitäten, Forschungsinstituten und Bildungseinrichtungen) sowie in Unternehmen anhand praxisorientierter Beispiele. Dabei werden sowohl grundlegende Modelle der Wissensorganisation als auch technische Umsetzungsmöglichkeiten erforscht und ihre Grenzen und Herausforderungen in der Praxis, insbesondere im Bereich der Wissensrepräsentation und des Semantic Web, thematisiert.
Best-Practice-Beispiele und erfolgreiche Anwendungsfälle aus realen Kontexten bieten den Lesern sowohl eine Wissenssammlung als auch eine Anleitung zur Umsetzung eigener Projekte.
Die Beiträge umfassen folgende thematische Bereiche: Hypertextbasiertes Wissensmanagement; digitale Optimierung der etablierten analogen Technologie des Zettelkastens; innovative Wissensorganisation mit Hilfe von Social Media; Visualisierung von Suchprozessen für digitale Bibliotheken; semantische Ereignis- und Wissensvisualisierung; ontologische Mindmaps und Wissenskarten; intelligente semantische Wissensverarbeitungssysteme; Grundlagen der computerunterstützten Wissensorganisation und -integration; das Konzept der Megaregionen zur Unterstützung von Suchprozessen und zur Verwaltung von Druckpublikationen in Bibliotheken; automatisierte Kodierung medizinischer Diagnosen; Beiträge zur Aktenverwaltung zur Modellierung und Handhabung von Geschäftsprozessen.
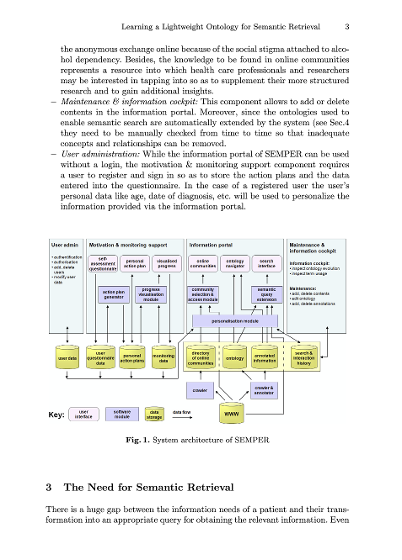
Learning a Lightweight Ontology for Semantic Retrieval in Patient-Centered Information Systems
https://www.igi-global.com/gateway/issue/47946
Ulrich Reimer (University of Applied Sciences St. Gallen, Switzerland), Edith Maier (University of Applied Sciences St. Gallen, Switzerland), Stephan Streit (University of Applied Sciences St. Gallen, Switzerland), Thomas Diggelmann (ai-one, Switzerland)
The paper introduces a web-based eHealth platform currently being developed that will assist patients with certain chronic diseases. The ultimate aim is behavioral change. This is supported by online assessment and feedback which visualizes actual behavior in relation to target behavior. Disease-specific information is provided through an information portal that utilizes lightweight ontologies (associative networks) in combination with text mining. The paper argues that classical word-based information retrieval is often not sufficient for providing patients with relevant information, but that their information needs are better addressed by concept-based retrieval. The focus of the paper is on the semantic retrieval component and the learning of a lightweight ontology from text documents, which is achieved by using a biologically inspired neural network. The paper concludes with preliminary results of the evaluation of the proposed approach in comparison with traditional approaches.

Official document download:
https://arxiv.org/pdf/2012.00614
Thomas Diggelmann, MSc ETH Physics, co-Founder and Head of Research at ai-one™ Inc.
CLIMATE-FEVER, a publicly available dataset for verification of climate change-related claims.
By providing a dataset for the research community, we aim to facilitate and encourage work on improving algorithms for retrieving evidential support for climate-specific claims, addressing the underlying language understanding challenges, and ultimately help alleviate the impact of misinformation on climate change. We adapt the methodology of FEVER [1], the largest dataset of artificially designed claims, to real-life claims collected from the Internet.
While during this process, we could rely on the expertise of renowned climate scientists, it turned out to be no easy task. We discuss the surprising, subtle complexity of modeling real-world climate-related claims within the \textsc{fever} framework, which we believe provides a valuable challenge for general natural language understanding.
The problem with the claims:
Fake news, alienated information, unsupported texts, false reports and even lies are gradually becoming known to all Internet users and many users are already affected by them.


